隨著傳統IDC向云數據中心轉型,數據中心網絡架構也在不斷演進。
在傳統的大型數據中心,采用了層次化模型設計的三層網絡。將復雜的網絡設計分成幾個層次,每個層次著重于某些特定的功能,這樣就能夠使一個復雜的大問題變成許多簡單的小問題。三層網絡架構設計的網絡有三個層次:
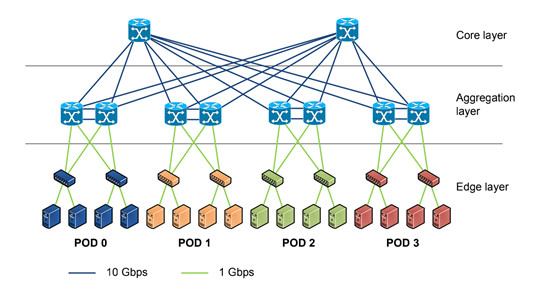
接入層(將工作站接入網絡)
接入層的面向對象主要是終端客戶,為終端客戶提供接入功能,接入層的主要功能是規劃同一網段中的工作站個數,提高各接入終端的帶寬。
匯聚層(提供基于策略的連接)
匯聚層連接網絡的核心層和各個接入的應用層,在兩層之間承擔“媒介傳輸”的作用。在應用接入核心層之前先經過匯聚層進行數據處理,以減輕核心層設備的負荷。匯聚層提供內容交換、防火墻、SSL卸載、入侵檢測、網絡分析等服務。
核心層(網絡的高速交換主干)
核心層在互聯網中承載著網絡服務器與各應用端口間的傳輸功能,是整個網絡的支撐脊梁和數據傳輸通道。核心交換機為進出數據中心的包提供高速的轉發,為多個匯聚層提供連接性,核心交換機通常為整個網絡提供一個彈性的L3路由網絡。
通常情況下,匯聚交換機是L2和L3網絡的邊界,匯聚交換機以下的是L2網絡,以上是L3網絡。每組匯聚交換機管理一個POD,每個POD內都是獨立的VLAN網絡。當服務器在一個POD內遷移時,不必修改IP地址和默認網關,因為一個POD對應一個二層廣播域。
在匯聚路由器和接入交換機之間,使用生成樹協議(STP)構建二層網絡的無環路拓撲。生成樹協議有幾個優點:它很簡單,是一種只需要很少配置的即插即用技術。但是,生成樹協議不能使用并行轉發路徑,往往會阻塞 VLAN 中的冗余路徑。
2010年,思科引入vPC(Virtual Port Channel)技術,消除了生成樹阻塞端口,提供從接入交換機到匯聚路由器的雙活上行鏈路,充分利用可用帶寬。但vPC也不能真正做到完全的水平擴展。
使用 vPC 進行數據中心設計
傳統三層數據中心網絡挑戰
三層網絡架構因其實現簡單、配置工作量小、廣播控制能力強等優點,被廣泛應用于傳統 DCN。但隨著數據中心整合、虛擬化、云計算等技術的發展,傳統三層網絡架構已經無法滿足網絡的需求,主要原因有:
無法支撐虛擬機遷移所需的大二層網絡構建
無法支持流量的無阻塞轉發(尤其是東西向流量)
虛擬機動態遷移
虛擬化技術從根本上改變了數據中心網絡架構的需求。通過服務器虛擬化可以有效地提供服務器利用率,按需提供服務和資源,降低能源消耗,降低客戶的運維成本,所以得到了廣泛的應用。
在虛擬化數據中心里,一臺物理服務器被虛擬化為多臺邏輯服務器,稱為VM,每臺VM都可以獨立運行,有自己的OS,APP,也有自己獨立的MAC地址和IP地址。
虛擬化出來以后,就產生了虛擬機動態遷移的需求,虛擬機動態遷移是指在保證虛擬正常運行的同時,將一個虛擬機從一臺物理服務器移動到另一臺物理服務器的過程。該過程對于最終用戶來說是無感知的,所以要保證在遷移過程中,虛擬機的業務不能中斷。
虛擬機在動態遷移時,不僅要求虛擬機的IP地址不變、而且運行狀態也必須保持(例如TCP會話狀態),這就需要遷移的起始和目標位置必須在同一個二層網絡域之中。
由于限制,傳統數據中心的三層網絡架構設計根本無法滿足服務器虛擬化中更靈活的、可自定義的虛擬機遷移策略。
為了實現虛擬機的大范圍,甚至跨地域的動態遷移,就要求把虛擬機遷移可能涉及的所有服務器都納用同一個二層網絡域,通過虛擬化的技術形成一個更大范圍的二層網絡。這樣才能實現虛擬機的大范圍無障礙遷移,這種適合虛擬機隨時隨地無障礙遷移的大范圍二層網絡,我們稱之為大二層網絡。
數據中心的流量的轉變
數據中心的流量總的來說可以分為以下幾種:
南北向流量:數據中心之外的客戶端到數據中心服務器之間的流量,或者數據中心服務器訪問互聯網的流量。
東西向流量:數據中心內的服務器之間的流量。
跨數據中心流量:不同數據中心的流量,例如數據中心之間的災備,私有云和公有云之間的通訊。
在傳統數據中心中,業務通常采用專線方式部署。通常,服務部署在一個或多個物理服務器上,并與其他系統物理隔離。因此,傳統數據中心東西向流量較低,南北向流量約占數據中心總流量的80%。
在云數據中心,服務架構逐漸從單體架構轉變為Web-APP-DB,分布式技術成為企業應用的主流。服務的組件通常分布在多個虛擬機或容器中。該服務不再由一臺或多臺物理服務器運行,而是由多臺服務器協同工作,導致東西向流量快速增長。
此外,大數據服務的出現使分布式計算成為云數據中心的標準配置。大數據服務可以分布在一個數據中心的數百臺服務器上進行并行計算,這也大大增加了東西向流量。
傳統的三層網絡架構是為南北向流量占主導地位的傳統數據中心設計的,不適合東西向流量較大的云數據中心。
一些東西向流量(如跨POD的二層和三層流量)必須經過匯聚層和核心層的設備轉發,不必要地經過許多節點。傳統網絡通常設置1:10到1:3的帶寬超額比,以提高設備利用率。隨著超額訂閱率,每次流量通過節點時性能都會顯著下降。此外,第 3 層網絡上的 xSTP 技術加劇了這種惡化。
因此,如果通過傳統三層網絡架構運行大量的東西向流量,連接到同一交換機端口的設備可能會爭奪帶寬,導致最終用戶獲得的響應時間很差。
Spine-Leaf架構
Clos 網絡以其發明者Charles Clos命名,Charles Clos是一名電話網絡工程師,他在 1950 年代需要解決如何應對電話網絡的爆炸式增長這一問題. 提出了現在稱之為 Clos 的網絡架構。
一個簡單的兩層Clos網絡
Spine-Leaf體系架構是由Spine和Leaf這兩個交換層組成的數據中心網絡拓撲結構。Leaf層由訪問交換機組成,匯聚來自服務器的流量,并直接連接到Spine或網絡核心。Spine交換機在全網格拓撲中互連所有Leaf交換機。上圖中,綠色節點代表交換機,灰色節點代表服務器。在綠色節點中,最上面的是Spine節點,下面是Leaf節點。
Spine-Leaf架構更適合滿足現代應用程序的需求,例如高吞吐量和低延遲。
Spine交換機具有高吞吐量、低延遲且端口密集,它們與每個Leaf交換機都有直接的高速 (40-400Gbps) 連接。
Leaf交換機與傳統TOR交換機非常相似,它們通常是 24 或 48 端口 1、10 或 40Gbps的接入層連接。但是,它們增加了到每個Spine交換機的 40、100 或 400Gbps 上行鏈路的能力。
Spine-Leaf架構與傳統網絡設計有何不同?
傳統數據中心的網絡通常基于三層模型:
接入交換機連接到服務器
匯聚交換機為接入交換機提供冗余連接
核心交換機在匯聚交換機之間提供快速傳輸
Spine-Leaf 架構減少了核心層,實現了層次的扁平化,如下圖所示。
此外,關于Spine-Leaf 架構的其他常見差異如下:
放棄了生成樹協議 (STP)
越來越多地使用固定端口交換機而不是網絡骨干的模塊化模型
橫向與縱向基礎架構的擴展
上文有提到如今東西向流量越來越多,低延遲、優化流量對于東西向流量的性能至關重要,尤其是在時間敏感或數據密集型應用程序中。Spine-Leaf架構的主要好處之一就是它允許數據流從數據的源到數據的目標路徑較短。無論源和目的地如何,Spine-Leaf結構中的數據流在網絡上的跳數都相同,任意兩個服務器之間都是Leaf—>Spine—>Leaf三跳可達的。
由于Spine-Leaf 架構不再需要 STP,容量也得到了提高。其依賴諸如 ECMP(等價多路徑)路由等協議來平衡所有可用路徑上的流量,同時仍然避免網絡環路。
除了更高的性能外,Spine-Leaf 架構還提供了更好的可擴展性。可以添加額外的Spine交換機并將其連接到每個Leaf ,從而進一步增加容量。同樣,當端口密度成為問題時,可以無縫添加新的Leaf 交換機。在這兩種情況下,網絡都不必為基礎設施的這種擴展(“橫向擴展”)而重新設計,也沒有停機時間。













 營業執照公示信息
營業執照公示信息